 en
en br
brTransactions in Firebird
Transactions in Firebird: ACID, Isolation levels, Deadlocks, and Resolution of update conflicts
Alexey Kovyazin, with the help of Vlad Khorsun and Dmitry Kuzmenko, 08-APR-2019Contents:
- How we will talk about transactions
- ACID in charts
- Transaction isolation levels in Firebird
- Resolution of update conflicts: Wait option
- True deadlock
Is it necessary to know how transactions work?
It is probably because the notion of transactions is simple, a lot of developers underestimate the importance of using transactions in Firebird correctly. However, only after you gain a thorough understanding of how transactions work, you can comprehend many mysterious things related to performance, such as sudden database slowdowns (connected with sweeping excessive record versions that appear due to bad transaction management).Generally, the notion of a transaction is applied to any dynamic system that moves from one state to another. For instance, a classic transaction example is transferring money from one account to another. Usually, it looks something like this:
Begin --- transferring money from account 1 to account 2 --decrease account 1 --increase account 2 End – committing the transactionThe example comes down to the fact that the money must disappear from account 1 and appear in account 2 simultaneously, otherwise, there will be either excess of money or unexplained lack of money for some time in the system.
From the standpoint of databases, a transaction is usually defined as a group of operations performed on a database that is seen as independent from other transactions. From my point of view, this definition is neither better nor worse than other definitions but, as any definition, it makes little sense without knowing the actual inner workings and logic of a DBMS.
It is believed that a transaction in a database must meet the so-called ACID requirements
A – Atomicity С – Consistency I – Isolation D - DurabilityMany developers of database applications are so much inspired by this acronym that they often use such arguments as "you have no D in ACID" when it comes to comparing different DBMSs (which is usually immediately followed by "I don't care what you think").
Actually, everything is rather simple – ACID is a set of requirements regarding the implementation of a transaction in a particular DBMS, some of them are very strict (for instance, D – of course, durability is important!) while some are less strict – when we look into the levels of transaction isolation, we will see that isolation may vary.
That is why it is not worth trying to immediately understand what this acronym literally means. Instead, we will examine the logic of how DBMSs (and transactions, in particular) work and view ACID from the standpoint of "how it is made" instead of "what it means".
How we will talk about transactions
Since transactions aspects are complex, we need a graphical representation - a kind of charts, to show transactions' work and interaction. Using these charts, we will be able to build a logical narration and look into the details of how transactions work.First of all, we will introduce a timeline because transactions develop in time. The timeline will be marked the way we need it – we need neither seconds nor minutes, but the key steps of interaction between transactions:

Then we will add a transaction onto this timeline – let us draw it in the form of a rectangle the sides of which will correspond to the start and end of the transaction. Since all transactions in Firebird are numbered, we will also specify the transaction number.
![]()
Thus, the chart shows transaction number 11 that started at the moment of time t3 and ended at the moment of time t10. There are two ways for a transaction to end – COMMIT, i.e. apply all changes made within the transaction, and ROLLBACK, i.e. cancel all changes made within the transaction. We will show the way a transaction ends in the following way:

To be able to go on, we will have to specify various parameters of transactions on these charts and we will specify them in the lower left corner of the rectangle representing the corresponding transaction – this example shows that transaction #11 has the snapshot isolation level.
![]()
When we say that "transaction X inserts data" or "transaction Y reads this and that data" - it is formally incorrect, because we should say "changes were made within transaction X". Only SQL statements can read or insert data so, if it is important for the narration, we will show these statements inside the transaction rectangle:
![]()
In this example, we have the INSERT operation for table T1, field i1, value 100 – this operation is performed within transaction #11 and it is committed.
Also, we will sometimes have to show the result of an operation, for instance, in the following example:
![]()
This example shows the following:
- Transaction #11 with the isolation level parameter set to snapshot (isolation levels will be discussed later, here it is shown just to draw the complete picture) is started at moment t3
- The operation INSERT INTO T1(i1) values (100) that inserts value 100 into field i1 of table t1 starts at moment t5 AND ends at moment t7
- The operation SELECT i1 from T1 that returns value i1 equal to 100 starts at moment t8
- Transaction #11 ends with the COMMIT statement, i.e. changes made by transaction #11 are committed to the database
Thus, with the help of transaction charts, we can describe in detail what goes on in the database and get to know how transactions work.
ACID in charts
Now when we have transaction charts, let us see what the ACID acronym really means.Atomicity
Atomicity means that either all operations making up a transaction are performed or none of them is performed: "all or nothing". It seems like a piece of cake, but then details come to light.First, the DBMS (not only Firebird but nearly all of them) has 2 types of atomicity: atomicity at the level of a statement and atomicity at the level of a group of statements within a transaction.
Atomicity at the statement level means that UPDATET1 SETX=1 WHEREY=2 statement is always either executed successfully or not.
Atomicity at the level of a group of statements works differently (we will use pseudocode here to mark when the transaction is started and committed):
Start transaction 11 INSERT ..100 INSERT ..200 INSERT ..300 Commit 11
This is what it will approximately look like on the chart:

It means that all three INSERT statements are successfully executed and changes made by them are committed at the moment when transaction #11 is committed.
The question that I often ask at workshops when it comes to transactions – will the COMMIT statement be successfully executed for transaction 11 if INSERT INTO..300 raises an exception:
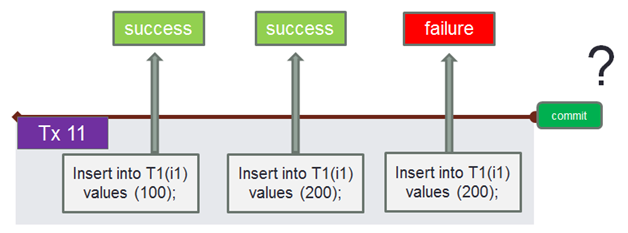
A considerable part of the audience always answers that the COMMIT statement will not be executed successfully! (Interestingly, it will cause the transaction to be rolled back in some other DBMSs!)
However, that is not true – just run isql and conduct an experiment with any database (isql has a simple and straightforward implementation of operations, without "guessing" for the user).
The thing is that atomicity on the level of statement groups ensured by transactions being committed is a question of business logic. The developer of an application has to decide whether a transaction should be committed in case of an exception in the third INSERT statement or not. If the business logic makes it possible to commit the result, the COMMIT statement can easily be executed.
Thus, the atomicity requirement in ACID is the requirement that the DBMS could commit or roll back the results of a group of statements executed within one transaction. The decision to commit it or roll it back depends on the business logic that you need to implement.
And let us underscore it once again — although the atomicity of a transaction for a group of statements means the possibility of committing or rolling back the entire group irrespective of the results (and the choice depends on the business logic), but the atomicity of one statement is guaranteed by the implementation of the DBMS, i.e. it is impossible to execute one statement (for instance, UPDATE) "incompletely" (not atomically).
Consistency
Consistency means that data inside the database presents no contradictions. Of course, here we can see a whole domain for speculation because "what does 'presents no contradictions' mean at all"?Two consistency levels are usually singled out:
- Database level where consistency means data correspondence to the database constraints, such as Primary, Unique and Foreign keys, Checks. This consistency level is ensured by the fact that database constraints will not make it possible to insert data that does not correspond to the constraints: e.g. CHECK(x>0) will not allow a negative number to be inserted into the corresponding field.
- Business logic level where the consistency is ensured by the developer of the application with the help of tools offered by the DBMS, such as transactions.
Starttransaction Decrease the amount of money in account 1…. Success Increase it in account 2… Failure Rollback ---- in case of an exception!
In other words, the developer must write code in such a way that the data is rolled back in case of an exception and thus the consistency of data is preserved from the standpoint of business logic.
This way, the consistency requirement in the ACID acronym means that it is necessary for the DBMS to have a possibility to sustain the consistency of data with the help of the transaction mechanism.
Isolation
The requirement of transaction isolation arises from the necessity to guarantee the result of a set of operations no matter what order they are performed in.Simply speaking, each transaction must be executed with one and the same result irrespective of transactions being concurrently active.
The mechanism of transactions is supposed to ensure consistency on the level of business logic, but it is also supposed to protect transactions against temporary unconfirmed data that may appear during the process of executing concurrent transactions.
It looks like this in practice:
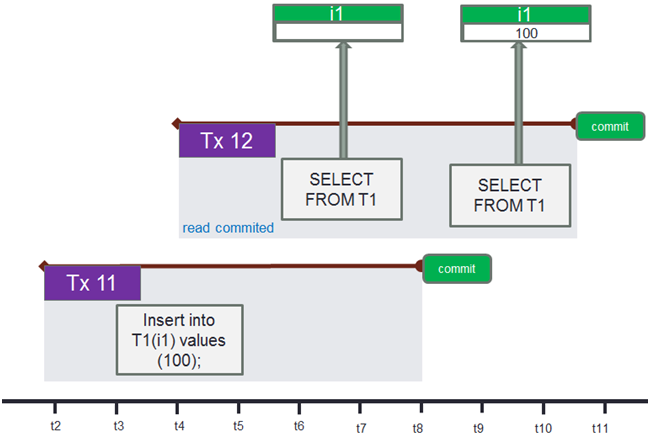
We see transaction #11 started at moment t2, within which an insert is made into the table at moment t3-t5. Transaction #11 is not committed right after the insert but continues to be active till moment t8.
Concurrently, transaction #12 is started and it executes the SELECT statement for the table records within transaction #11 are inserted to. The first SELECT statement is executed at moment t6, which is when the insert operation is already over, but this statement returns an empty result because transaction #12 cannot see uncommitted data from other transactions.
Transaction #11 is committed at moment t8 and the SELECT statement within transaction #12 is executed at moment t9. It returns the result equal to 100 because the data created within transaction #11 is now committed (and because the isolation level of transaction #12 is read committed, but we will talk about it later).
This example is quite enough to illustrate the isolation requirement – unlike atomicity and consistency, isolation is implemented as strict rules called isolation levels and each transaction must have a parameter that sets the isolation level it works with.
Durability
The concept of durability allows the developer to entirely rely on the fact that data created within a committed transaction will immediately appear in the database and will not disappear from it (without explicit statements that delete or change it, of course) no matter what happens next.As you can see, the durability requirement is just common sense – hardly would anyone agree to use a system data from which may disappear all of a sudden.
ACID: summary
ACID means the requirements of how transactions must work:- Atomicity
- Statements are always atomic
- Groups of statements can be made atomic with the help of transactions
- Consistency
- Two consistency levels: database constraints and business logic
- Isolation
- Ensured by the mechanism of transactions with the help of isolation levels set for them
- Durability
- All committed data becomes permanent
Transaction isolation levels in Firebird
The isolation level of a transaction defines which committed data this transaction can see.
There are isolation levels that are conventionally called standard. They are described in the ANSI SQL standard (various revisions). As far as I know, there is not a single DBMS where they are implemented exactly the way they are described in the standard, but nobody is worried about that since the actual mechanisms of transactions in specific DBMSs have all the necessary options for implementing the business logic.
You can find the classic definition of isolation levels in "A Critique of ANSI SQL Isolation Levels"
For those who have read this article, here is the table comparing the classic isolation levels with similar ones in Firebird. Of course, the correspondence is not straightforward because isolation levels in Firebird, as well as in other DBMSs, do not comply 100% with the ANSI SQL definitions, but they are very similar to them.
| ANSI Isolation Levels | Isolation level in Firebird |
| Read Uncommitted | n/a |
| Read Committed | Read Committed |
| Repeatable Read | Snapshot |
| Serializable | Snapshot table stability |
As any other DBMS, Firebird has its peculiarities in the implementation of isolation. Now we will focus on how isolation levels work in Firebird, instead of how well they comply with the standard.
Snapshot isolation level
The Snapshot isolation level was the first in the original code of InterBase and remains the default one for the Firebird core API and utilities (for instance, isql.exe). This may be the reason why it is the easiest one to understand.Snapshot isolates the transaction from any changes made from the moment of its start.
Let us take a look at the transaction chart below: it shows transaction #10 started with the snapshot isolation level. Within this transaction, several SELECT statements are made for table T1 that has no records in this example.
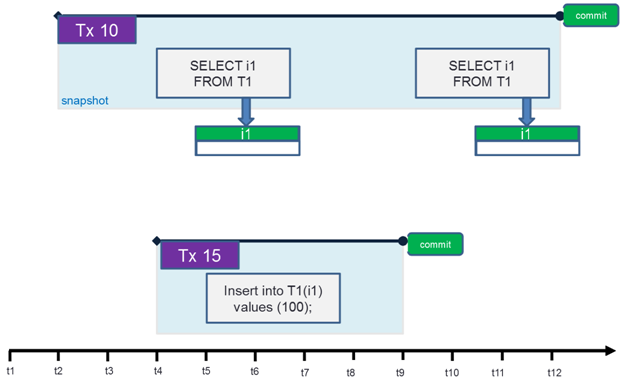
Concurrent transaction #15 started after the start of transaction #10 inserts data into table T1 and this transaction ends with the COMMIT statement at moment t9, i.e. the data is committed to the database at this moment and is available for statements from other transactions.
However, the statement in transaction #10 executed at moment t10 (i.e. after transaction #15 is committed) does not see the inserted data because the snapshot isolation level allows it to see only committed data inserted or changed BEFORE THE START of transaction #10.
Thus, the Snapshot isolation level allows you to work with the database as if it is frozen at the moment the transaction starts. It is usually necessary to build complicated reports based on quickly changing data: snapshot is used in order to avoid the situation when the first part of the report is based on some data and the last part is based on different data.
However, this great feature has its price - when we later examine how isolation is implemented in Firebird, you will see that starting very long transactions with the snapshot isolation level results in excessive record versions and lower performance.
Read Committed isolation level
A transaction with the read committed isolation level can see the committed data of other transactions that are committed while it is active (unlike it is the case with the snapshot level, when you can see only data committed before the moment the transaction starts).
Let us show how the read committed isolation level works using the following chart:

It shows an example practically identical to the previous one: two concurrent transactions one of which regularly reads data from table T1 while the second one inserts and commits data.
Unlike the case with the snapshot isolation level, transaction #10 in this example sees the data inserted and committed by transaction #15.
This example gives us an idea about the impact of the read committed isolation level: statements within a transaction with this isolation level can see data committed before the moment the corresponding statement is executed.
The next chart shows an example where two concurrent transactions #11 and #18 change data.
Note that transaction #11 starts before the start of transaction #14 that reads data while transaction #18 starts after it, but it does not affect the result: if the data is committed, it can be seen by the concurrent transaction with the read committed isolation level.

This possibility makes the read committed isolation level a natural choice for those SQL statements that are regularly executed in order to show the latest database state (for instance, in order to show the latest orders).
The part devoted to garbage collection will show that read committed transactions with the read-only modifier in Firebird up to version 4 are the best choice for "infinite" read transactions because they are started as pre-committed.
Snapshot table stability isolation level
It is possible to make the story about the snapshot table stability isolation mode, which is a counterpart to the standard Serializable isolation mode, either very short or quite long and detailed.The short version of the story is the following: this level is completely similar to the snapshot level with additionally locking the table (the table must be explicitly specified in the transaction parameters) for writing and reading. It means that it is possible to start a transaction that will fully occupy the specified table and any other transactions will get access errors.
In other words, a transaction with the snapshot table stability isolation level will actually put all queries to the specified table in a queue. In fact, only reads in regular transactions will be made out of their turn (as usual) while all other modes will form a queue (it depends on the interaction, of course).
If implemented without caution, it may cause locks and impossibility to work with the database that is why Firebird database application developers may be afraid to use this isolation level.
However, if implemented correctly, the Serializable isolation level makes it possible to easily form queues and make sequential changes in database records, which may be very useful to implement counters, sequential document numbers and other objects like that.
To correctly describe how to form a queue with the help of a transaction with the snapshot table stability isolation level, we will have to look into one more transaction parameter: wait/nowait - and then get back to the queue example.
Resolution of update conflicts: Wait option
Previously we examined such a way of interaction between transactions that data is changed within one transaction and it is read within another transaction.However, it often happens in practice when different transactions try to change the same data and since only one result is saved in the database, the concurrent transaction will get a conflict message – in fact, an exception that will interrupt (and cancel) the execution of that specific statement that is trying to change the already changed data.
The wait option defines how a transaction should react to the update conflict. There are three ways of configuring this option:
- Wait (no parameters) = wait until the concurrent transaction ends
- Wait Timeout N sec = wait until the concurrent transaction ends, but not more than N seconds
- Nowait – do not wait until the concurrent transaction ends
Let us see in detail what happens in case of update conflicts with various variants of the wait option.
Wait
So, let us imagine two concurrently active transactions (#11 and #14) within which the UPDATE statement is executed that must change one and the same record in one and the same table T1.Transaction #14 runs with the wait option (if you use isql to reproduce the examples, wait is set by default).
The UPDATE statement in transaction #11 starts at moment t3 and ends at moment t5, but the transaction is not committed yet – i.e. the COMMIT statement is not there till moment t6.
The chart below shows this situation:
![]()
The UPDATE statement is also executed in transaction #14 and it tries to update the same record in the same table, but it starts later – approximately at moment t4.
Since there is an update conflict with the update from transaction #11 and wait is specified in transaction #14, the UPDATE statement will wait until conflicting transaction #11 ends.
If transaction #11 lasts long enough, the UPDATE statement in transaction #14 will seem frozen from the standpoint of the user watching the execution of this statement.
If you reproduce this situation with the help of two isql.exe, the next picture shows the moment when the second transaction (to be exact the transaction where the concurrent UPDATE statement starts later – it is transaction #14 in our example) waits until the first transaction ends (it is transaction #11 in our example).

After the COMMIT statement is executed in transaction #11, transaction #14 waiting for it will be immediately notified and the conflicting update will end with an exception.
Below you can see an example of such an error message (the number of the concurrent transaction does not coincide with our example because the numbers of transactions start from the beginning in each database and then only increment while being reset only after backup/restore):
SQL> update T1 set i1 = 2 where i1=1; Statement failed, SQLSTATE = 40001 deadlock -update conflicts with concurrent update -concurrent transaction number is 19 SQL>
Pay attention to the word "deadlock" in the error message – now there is actually no deadlock according to its classic definition. Instead, there is an update conflict, but Firebird developers do not change the error message because it has been used for more than 35 years. We will deal with the true "classic" deadlock later.
So, we have examined the situation when the transaction with the concurrent UPDATE statement ends with the COMMIT statement. Let us now take a similar situation, but when it is rolled back – you can see it on the chart below:

Thus, the wait option makes it possible to organize the business logic of updates in such a way that conflicting updates infinitely wait in a queue hoping till the last moment that the transaction conflicting with them ends with the ROLLBACK statement.
Does this tactic always make sense? Of course, it depends on the implementation of the business logic, but Firebird offers other options as well for resolving update conflicts with the help of the wait option.
Wait with timeout
First of all, it may be a good idea to limit the time of waiting – instead of infinitely waiting in case of a conflict, you can limit the time of waiting by specifying a timeout for the wait option.In isql.exe such a parameter is specified with the help of the following statement:
SET TRANSACTION WAIT LOCK TIMEOUT N;Where N is time (in seconds) that the concurrent transaction will wait for the conflict to be resolved.
You can find more details about transaction control statements in Firebird Language Reference. Note that there may be different ways to specify the timeout in specific drivers or access components (usually, with the help of the API parameter).
You can see an example in isql in the picture below:

Let us study with the help of transaction charts how transactions interact if you specify the timeout for the wait option.
So, the situation is the same – two concurrent transactions #11 and #14 within which the UPDATE statement trying to update one and the same record in table T1 is executed.
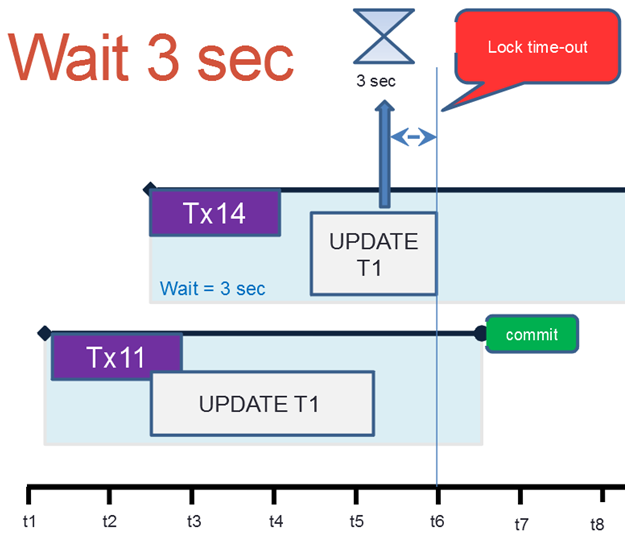
However, in this case, the statement within transaction #14 waits either until transaction #11 ends or until the specified timeout (3 seconds) expires – whichever comes first.
The timeout expires earlier in this example, the statement ends with an exception:
SQL> update T1 set i1=6 where i1=1; Statement failed, SQLSTATE = 40001 lock time-out on wait transaction -deadlock -update conflicts with concurrent update -concurrent transaction number is 40
Note that "deadlock" is again in the error message, but it is still not a "true" deadlock.
Correspondingly, the situation is similar to that with the wait option, but it is limited by the timeout – if the specified timeout expires earlier than the concurrent transaction ends.
Specifying the wait option with timeout may be a good solution to implement business logic if you know for sure that all writing transactions are quite short (for instance, not longer than 1-2 seconds).
Nowait
It is very easy to explain what Nowait is from the formal point of view – it is wait with zero timeout. If you specify nowait in transactions, conflicting updates will raise an exception immediately.
SQL> update T1 set i1=5 where i1=1; Statement failed, SQLSTATE = 40001 lock conflict on no wait transaction -deadlock -update conflicts with concurrent update -concurrent transaction number is 50 SQL>Here is what it looks like in an example with two isql tools:
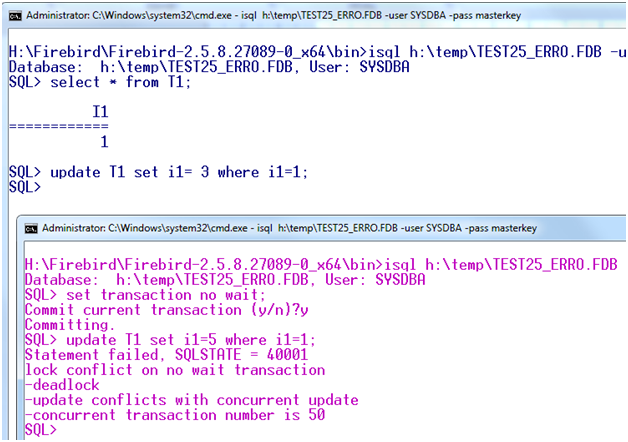
From the standpoint of business logic, the nowait transaction can be convenient if you know for sure that the concurrent update must result in undoubtedly cancelling the actions of the current statement.
Many Firebird drivers use the nowait option as the default value and, as long as many developers do not know that it is possible to set a less strict level for resolving update conflicts (for instance, wait lock timeout 1), their applications (and sometimes users as well) suffer from unnecessary errors due to conflicts.
True deadlock
Since the keyword "deadlock" is present in each exceptions related to update conflicts, a lot of application developers are sure that this is what a true deadlock actually is (some even think that very Dead had a role in this error).At the same time, if we have a look at the configuration file firebird.conf, we will see the DeadlockTimeout parameter there (it is 10 seconds by default), and if we look at the output header of the fb_lock_print utility, we will also see the "Deadlock scans" parameter.
The thing is that a "true deadlock" is possible in Firebird and the keyword "deadlock" appearing in all exceptions related to update conflicts has no direct connection to it. Fortunately, the true deadlock occurs rather rarely.
Let us see what this "true deadlock" is. To do it, take a look at the following chart of transaction interaction:

- Transaction #11 updates the record with the key = 20, and transactions #12 updates the record with the key = 10;
- After that, transaction #11 updates the record with the key = 10, and transactions #12 updates the record with the key = 20;
We can reproduce this situation with the help of two isql:

Note that the client (isql in this case) gets a regular update conflict message, but it is initiated in 10 seconds even if the transaction is started with the wait option.
After the server detects the interdependent lock of two transactions, it will also increment the internal deadlock counter (you can see it in the fb_lock_print output).
Practical use of Snapshot Table Stability
Now that we know how transactions work with conflicting UPDATE statements, we can get back to the Snapshot Table Stability isolation level and find a practical use for it.So, when this isolation level is specified, the table is locked for writing and even for reading.
Note that if the table in the transaction parameters is not explicitly specified, all tables statements access within this transaction are locked and it happens during the first access to a table. Apparently, if this isolation level is used without caution, it will easily lead to a large number of update conflicts.
The Reserving TableNN clause allows you to specify a particular table (or several tables) to be locked at the beginning of the transaction (it is also possible to specify the reserving mode).
This great feature together with the wait option allows you to implement a very effective sequential queue for changing a specific table.
In practice, it looks like this — those clients that need to create a queue to a particular table start the SNAPSHOT TABLE STABILITY transaction specifying this table and then they try to perform within this transaction an operation and end it immediately.
For instance, we want to create a sequentially incrementing counter in a table with the only record of the CREATE TABLE Table1(i1 integer not null) type, but we cannot use a generator for some reason.
The pseudocode looks approximately like this:
set transaction snapshot table stability reserving TABLE1 for protected write UPDATE Table1 Set i1 = i1+1; SELECT i1 from Table1; COMMIT;
If we run this code not with the Snapshot Table Stability (Table1) isolation level, but with a lower isolation level, it will be possible that a concurrent UPDATE statement interferes between the start of the transaction and before its UPDATE statement. As a result, we will get either an update exception at once (nowait) or the statement will freeze till the end of the concurrent one (wait) or the timeout (wait interval) — in other words, the conflict will be somehow resolved on the statement level.
With the snapshot table stability isolation level, we are ensured against it because the table is reserved at the beginning of the transaction — it is either entirely ours or entirely not ours. If we specify the wait option for resolving conflicts, the parallel connections will automatically form a queue without handling any errors.
Of course, this approach can be applied only to short transactions (the way it is in our example).
In practice, the Snapshot table stability isolation level is used to form queues and recalculate complex logic in the exclusive mode (in relatively small tables or when there are no other users).
Inside the engine, Firebird uses the Snapshot Table Stability isolation level to create indices — i.e. when you execute the ALTER INDEX indexname ACTIVE; statement, Firebird will completely occupy the table the index is being built for.
What Next?
This article gives only the introduction to the concepts of Firebird transactions. To completely understand how transactions work in Firebird, it is necessary to consider multi-generational architecture (record versions and garbage collection concepts), consider transaction markers (Oldest Interesting, Oldest Active, Oldest Snapshot, next) and other things.The article is based on the materials of "All About Transactions" seminar/workshop, which was first introduced in 2013 during the Firebird Tour seminars, and on the basis of IBSurgeon's training "Firebird Transaction in details".